Daniel Lemire and I have spent some time this year working on a fast JSON parser. You can read about it in paper form at arXiv here and the repo is here.
In this blog post, I’ll provide an informal summary of the paper and some background as to the thinking behind the system.
What it is
simdjson is a parser from JSON input to an immutable tree form (a “DOM” in XML terminology). It’s not a full-featured library; it doesn’t allow you to modify the JSON document and write it back out.
simdjson is a fully featured parser – it doesn’t just scan through bits of the JSON looking for particular fields. That’s an extension which we have thought about but we don’t really have good benchmarks for that.
simdjson validates its input. Being generous about accepting malformed input is a rabbit hole – how do you define the semantics of handling a malformed document?
Here’s our performance, against the closest C/C++ competitors we measured, on a range on inputs on a Intel Skylake processor (a i7-6700 running at 3.4 GHz in 64 bit mode) – for full performance details, read the paper!
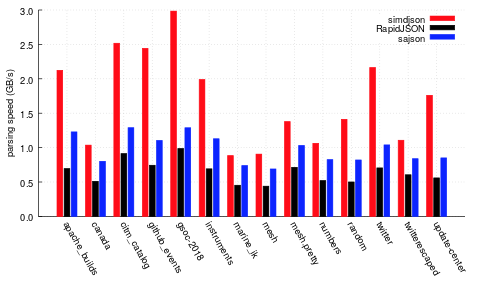
It’s pretty fast – we seem to be 2-3x faster than the next most reasonable alternative (the primary sources of variability are string and number handling – different JSON documents have different amounts of this kind of work to do). We’re probably competitive with Mison (one of our major inspirations) but we don’t have source code so we can’t tell – and we’re doing a lot more work than Mison. Specifically, Mison isn’t validating and doesn’t build a parse tree.
We provide everything required to repeat our experiments, so if you want to verify our results or test them under different assumptions or against different workloads or parsers, it should be very easy to do that.
Why it is fast
The chief point of difference between simdjson and systems such as RapidJSON and sajson lies in the “Stage 1” of simdjson; the part of the system that detects the locations of structural and pseudo-structural characters from the input. This system operates with large scale and regular operations over 64 bytes of the input at once, and can take advantage of both SIMD operations (when examining characters and character classes) as well as 64-bit bitwise operations (when applying transformations on the masks obtained from the SIMD operations). As such, it can achieve “economies of scale” as compared to a step-by-step approach.
For example, an input that consists of a section comprising two key/value pairs:
“result_type”: “recent”,
“iso_language_code”: “ja”
… enters and leaves the condition of ‘being in a string’ 4 times in under 64 characters. A loop which involves step-by-step scanning of our input would typically not benefit from SIMD due to the relatively short stings, and will need to perform relatively slow operations to detect the next string delimiter. By contrast, our stage 1 code would detect all string begin and end markers with a fixed-cost set of operations (albeit an admittedly complex set). Further, our code can do this without data-dependent conditional branches, which will bring our pipeline to a crashing halt on the the first mispredict.
How it works
Just like the old Soviet-era joke about ‘mat’ (the amazing sub-dialect of Russian swearing) usage by workers in the missile factory, we have two stages, and one goes into the other.
There used to be four stages, and this may show up in a few places in old issues and comments.
Stage 1 uses SIMD to attempt to discover the significant parts of the document that need to be fed into the parser, which is Stage 2. The job of Stage 1 is not necessarily to validate what happens. Instead, the job of Stage 1 is to expose what Stage 2 needs to see – so we need to find the set of structural characters such as [, ], {, }, comma, colon, etc. but we also need to find potential starting characters for atoms such as “true”, “false”, “null” and the numbers. Further, we need to find the starts of errors – so if whitespace or one of these other structural characters is followed by some erroneous string, we need to expose that string to stage 2 to reveal an error.
These subsidiary not-quite-structural characters we refer to as “pseudo-structural characters”: things falling after whitespace or other structural characters, that are not safely tucked inside strings. There’s a fair bit of bit-bashing to find them, but it is all quite mechanical.
To get all the way through stage 1 is a fairly mechanical straight-line process. It is almost entirely branch-free, with a couple exceptions (UTF-8 checking and handling of large numbers of structural characters at the end of stage 1). Stage 1 proceeds as follows:
- Validation of UTF-8 across the whole input.
- Detection of odd-length sequences of backslashes (that will result in escaping the subsequent character)
- Detection of which characters are “inside” quotes, by filtering out escaped quote characters from the previous step, then doing a parallel prefix sum over XOR (using the PCLMULQDQ instruction with an argument of -1 as the multiplier) to turn our escaped quote mask into a mask showing which bits are between a pair of quotes.
- Detection of structural characters and whitespace via table-based lookup (implemented with a pair of VPSHUFB instructions).
- Detection of pseudo-structural characters (those characters I talked about in the summary of stage 1 that need to be exposed to the subsequent stage 2 for error detection and atom handling).
- Conversion of the bitmask containing structural and pseudo-structural characters into a series of indexes.
Stage 2 is considerably less clean and branch free. It operates as a goto-based automata with a stack and validates that the sequence of structural and pseudo-structural characters that have passed in correspond to valid JSON. It also handles atom, number and string validation and, as it goes, constructs our ‘tape’ representation (a navigable, if immutable, tree of JSON elements).
If there’s enough interest, I may do a detailed code walk-through. It’s my belief that many of the steps are fairly novel or novel; to my knowledge, I invented the use of PCLMULQDQ to balance quote pairs for this work and the PSHUFB-based table lookup was also my invention while I worked on the Hyperscan project (which continues, at Intel, unburdened of its awkward load of Australians). However, it would not surprise me to find that many of the techniques are independently invented somewhere else: we found that we had independently invented the techniques used in the remarkable icgrep and the technique that I was so proud of in “Sheng” had been invented by Microsoft before. So maybe one day I’ll invent something of my own for real…
Why it exists – what’s the idea here?
We were curious about how far parsing can be done with SIMD instructions. Stage 1 represents the current limit for us – Stage 2 is only sporadically SIMD and is extremely branchy. So we got as far as we could.
It’s worth stepping back and talking about the original 4-stage design. Initially the bits->indexes transformation occupied a separate stage, but why were there stages 3 and 4? Initially, stage 3 was branch free. It operated over the indexes, but through a series of supposedly clever conditional moves and awkward design, it was able to process and validate almost everything about the input without ever taking a branch (for example, it used a DFA to validate most of the local correctness of the sequence of structural and pseudo-structural characters). It also built a very awkward predecessor of our ‘tape’ structure, with just enough information to traverse our tapes. It then deferred all awkward ‘branchy’ work to a stage 4 (handling of validation of individual atoms, ensuring that {} and [] pairs matched, number and string validation, and cleanup of the awkwardness of the tape structure allowing a more conventional traversal of the tapes).
Fun fact: stage 3 was originally called the “ape_machine” (being a combination of a state_machine and a tape_machine), while stage 4 was the “shovel_machine”, which followed the ape_machine and cleaned up its messes.
Those who have worked with me before may recognize the penchant for cutesey code-names; simdjson doesn’t really have any, now that the ape and shovel machines are put out to pasture. We couldn’t even think of a particularly good name (sadly “Euphemus”, helmsman for Jason and the Argonauts, has already been taken by another project with a similar general task area, and none of the other Argonauts have names that are nearly as amusing).
While stage 3 wasn’t SIMD, it was branch-free and thus avoided the awkwardness of branchy, conditional-heavy processing. Thus, in theory, on a modern architecture, it could run very fast, overlapping the handling of one index with the handling of the next index. The problem is that it pushes a bunch of awkward, branchy work into stage 4.
The sad truth is: sooner or later, you have to take the conditional branches. So pushing them into a late stage didn’t solve the problem. If there is a certain amount of awkward conditional work do to, eventually one must do it – this is the software equivalent of the psychoanalytic “return of the repressed“.
Thus, our new “stage 2” is the pragmatic alternative. If we’re going to take unpredictable branches, we may as well do all the work there.
I’m still on the hunt for more parallel and/or branch-free ways of handling the work done in stage 2. Some aspects of what we are doing could be done in parallel (computation of depth and/or final tape location could likely be done with parallel prefix sum) or at least fast (we could go back to a fast automata to handle much of the global validation or the local validation of things like numbers and strings). But the current system is pretty fast, so the parallel system would have to work really well to be competitive.
It’s still worth thinking about this for more modern or upcoming architectures (AVX 512, ARM’s SVE) or unusual architectures (the massive parallelism of GPGPU). This would be a good research project (see below).
What next? (and/or “I’m interested, how can I help?”)
There are a few interesting projects in different directions. Similar tricks to what we’ve done could be used for other formats (notably CSV parsing, which should be doable with something analogous to our stage 1). We could also try to extend these techniques more generally – it’s our hope that a more systematic version of our SIMD tricks could be picked up and incorporated into a more general parser.
There’s quite a bit of software engineering still to do with the JSON parser if someone wants to use it as a generally usable library. It’s a few steps beyond the typical caricature of an academic project (“it worked once on my graduate student’s laptop”) but it isn’t really battle-hardened.
The structure of simdjson is not particularly oriented towards reuse. A helpful set of transformations would be to break it into smaller, reusable components without compromising performance. Particularly egregious is the use of many hard-coded tables for the VPSHUFB-based character matcher; not only does this hard code the particular characters and character classes, it cannot be reused in a situation as-is in a number of situations (e.g. overly numerous character classes or ones where a desired character class includes one with the high bit set).
The aforementioned work with retargeting this work to AVX512, ARM NEON, ARM SVE or GPGPU (CUDA or OpenCL) would be interesting as an exercise. These are varying degrees of difficulty.
Note that there are some opportunities to engage in SIMD on a more massive scale – we could use SIMD not just for character class detection but for many of the intermediate steps. So we would process, on AVX512, 512 characters at once, then do our various manipulations on 512-bit vectors instead of 64-bit words. There are some nice possibilities here (including a fun sequence to calculate XOR-based parallel prefix over 512 bits rather than 64; a nice challenge that I have worked out on paper but not in practice). We also have examined bits->indexes for AVX512 as well. However, this may fall into the category of the drunk man “looking for their keys under the lamppost not because he dropped them there, but because the light is better”. It is Stage 2 that needs to be made parallel and/or regular, not Stage 1!
An ambitious person could attack Stage 2 and make it considerably more parallel. I confess to having failed here, but a patient soul may benefit from my copious notes and half-baked ideas. If you are serious, get in touch.
Acknowledgements
Daniel Lemire provided most of the initial impetus towards this project, put up with a ludicrous churn of ideas and half-formed implementations from me, handled many of the tasks that I was too fidgety to do properly (number handling, UTF-8 validation) and did nearly all the real software engineering present in this project. Without his ceaseless work, this code would be a few half-formed ideas floating around in a notebook.
The original Mison paper (authors: Yinan Li, Nikos R. Katsipoulakis, Badrish Chandramouli, Jonathan Goldstein, Donald Kossmann) provided inspiration for the overall structure and data-flow of the earlier parts of ‘stage 1’ – our implementations are different but the early steps of our Stage 1 follow Mison very closely in structure.
The vectorized UTF-8 validation was motivated by a blog post by O. Goffart. K. Willets helped design the current vectorized UTF-8 validation. In particular, he provided the algorithm and code to check that sequences of two, three and four non-ASCII bytes match the leading byte. The authors are grateful to W. Mula for sharing related number-parsing code online.
Post-script: Frequently Unanswered Questions
- How much faster could this run if the JSON was in some weird format e.g. “one record per line”?
- Why do people use so much JSON, anyhow? Why don’t they use a more efficient format?
- Why not write this in <insert favorite language X here>? Wouldn’t a rewrite in X be just inherently better/faster/safer?

[…] We have paper full of benchmarks and my co-author (Geoff) has a great blog post presenting our work. […]
LikeLike
[…] technique that we recently disclosed for our JSON parser (see the paper or recent blog post) is something I think I invented (please set me straight if this is known since the glory days of […]
LikeLike
I don’t get the Australian reference in the article. Care to explain?
LikeLike
The 4-person engineering team that built Hyperscan at Sensory Networks was based in Sydney, Australia. Intel acquired Sensory Networks in 2013, but the Sydney-based team was made redundant in 2018. Hyperscan development continues based out of Intel Shanghai.
LikeLike
If you want speed, don’t use JSON. It’s a truly disgusting format, with no redeeming features besides (historical) JavaScript interop.
LikeLike
I wouldn’t recommend people use JSON if starting with a clean slate, but there’s tons of JSON out there and it’s not always possible to choose.
LikeLike
I am really delighted to glance at this blog posts which consists
of lots of valuable data, thanks for providing these statistics.
LikeLike
Amazing work, thank you! I know this was covered in “FUQs” section, but I am really wondering what a text-based (human readable) format designed for parse performance would look like.
LikeLike
Thanks! I’m not sure how I would change such a format to try to simultaneously improve both performance while still keeping things readable and human-understandable. While we write a lot about “Stage 1”, much of the performance leaks away in the parts of the code that are not currently branch-free – the bits to indices code and of course our Stage 2, the parser. Many of the little ‘tweaks’ you could do to the format might simplify stage 1, but that’s not really the place where performance improvements could be made.
A quirky possibility would be to go Python-style and insist on a certain number of tabs or spaces as a mandatory and consistent indication of nesting depth. Being able to *instantly* figure out nesting depth while looking at a fairly shallow depth would have a lot of benefits for designing a new algorithm – one could blast out what we call “tape” records onto the appropriate depth with only a shallow and simple analysis.
LikeLike
Amazing work, thank you! I know this was covered in “FUQs” section, but I am really wondering what a text-based (human readable) format designed for parse performance would look like.
LikeLike
[…] 我們也有一個非正式的部落格文章提供了一些背景和情境。 […]
LikeLike