Today I’m going to share with you one of my favorite instruction sequences.
PSHUFB
PAND
PSUBB
PCMPGTB
PMOVMSKB
ANDN
ADD
AND
AND
LOAD
OK, got it? That’s the post. Have a nice day.
Perhaps a little more explanation is in order, especially if you weren’t next to my cubicle for what were no doubt 11 very long years during the creation of Hyperscan. The above sequence, which I have dubbed SMH (an acronym which stands for “I am Not Going to Explain”), appears in various forms in Hyperscan, and has a few expansions and variants which I’ll discuss. I think a full expansion of all the fun of SMH, and a codebase to match, will have to wait.
This sequence looks fairly banal – but it can accomplish a huge range of matching tasks, not all of which are traditional pattern matching tasks. Let’s walk through a basic application and we’ll get to more elaborate ones in later posts.
Keep in mind that the basic unit here is asking questions composed of a bunch of byte-level predicates comparing our input to queries we prepared earlier.
The code for this is up at Github at: Shuffle-based predicate matcher and all-round branch free swiss army chainsaw
Baseline Application: Prefix Matching
Everyone likes a good Prefix Matcher – Prefix or Suffix matchers crop up all over the place in pattern matching as a basic building block. There are plenty of traditional implementations of this (generally involving DFAs or hashing/Bloom Filters).
I’m going to focus on a case that allows SMH to be displayed without too much extra complexity: small-set Prefix matching of literal strings no greater than 16 characters.
Suppose we want to match a few animal names and map those to some sort of id: we have {“cat”, “dog”, “mouse”, “moose”, …}. Here’s a straightforward approach to doing this, assuming we have no more than 32 characters overall in total and a machine handy with AVX2 (if you don’t, buy yourself a better computer and give Grandpa back his Ivy Bridge, or translate everything I’m saying into Neon – there’s nothing here that’s all that Intel specific, but I don’t have a fast ARM workstation so y’all can suck it up and read AVX code):
- Load 16 bytes of our input from memory and broadcast it to high and low lanes of an AVX2 register
- Shuffle the input with a pre-prepared shuffle mask, so that we can consecutively compare the first 3 bytes against cat at bytes 0..2 of our register, the first 3 bytes again against ‘dog’ in bytes 3..5 of our register, etc.
- Compare the input against another pre-prepared mask, this one containing our strings: so the register would pack in ‘catdogmousemoose’.
- Use VPMOVMSKB to turn the compare results (which will be 0x00 or 0xff) into single bits in a general purpose register (now, you can put your SIMD units away).
These steps are illustrated below:

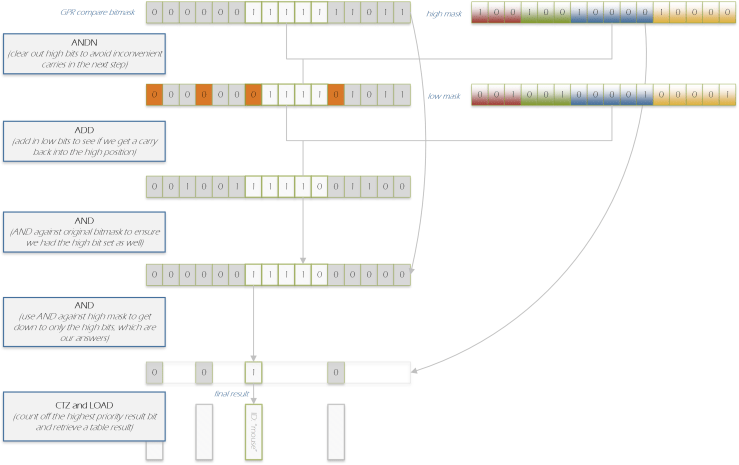
- Take the Most Significant Bit of each string in the mask – if we are packing our strings from left to right (it doesn’t really matter which way we do the comparisons) we would have the comparison of ‘cat’ so that ‘c’ is in bit 0, ‘a’ is in bit 1, ‘t’ is in bit 2, and we would declare the bit 2 part of our Most Significant or “high” end, so bit 2, 5, etc. would be our high mask. We’re going to make a temporary mask which is the result of our VPMOVMSKB with the ‘high’ mask zeroed out.
I refer to this as ‘digging a hole’. We’ll need that ‘hole’ later. - Now take the corresponding ‘low’ mask (the LSB end of each string) and simply add it to our temporary.
The effect of this will be that if, and only if, all our other bits in the mask are on, there will be an arithmetic carry into that ‘hole’ I mentioned (and you can see why we needed it – we certainly don’t want to carry beyond that point). - Now AND the original mask (not the high mask, but the original mask we got from PMOVMSKB back in). Now the high bits are on if and only if every comparison bit associated with the string is on.
- We then AND by our high mask again to turn off everything but our high bits.
- We can use LZCNT (leading zero count) to find our first high bit that’s set. We pack our strings in order of priority, so the ‘winning bit’ (in case two bits are on – possible if our strings or later patterns overlap). We don’t have to do it this way – we might want to report all matches. For now, we’ll report a highest priority match.
- This LZCNT is then used to read from a table that has ID entries only for the bits that have high bits set (the other entries in the table are never read – this wastes some space but means we don’t need to compress down our table).
Steps 5-10 are illustrated here:
So – that’s the basic algorithm.
This gist shows the edited highlights (no debugging guff – I have some code that prints out the process in greater detail if that’s what you’re into) of steps 1-9: there’s really not that much run-time code.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| struct SIMD_SMH_PART { | |
| m256 shuf_mask; | |
| m256 cmp_mask; | |
| m256 and_mask; // not yet used | |
| m256 sub_mask; // not yet used | |
| u32 doit(m256 d) { | |
| return _mm256_movemask_epi8( | |
| _mm256_cmpeq_epi8(_mm256_shuffle_epi8(d, shuf_mask), | |
| cmp_mask)); | |
| } | |
| }; | |
| struct GPR_SMH_PART { | |
| u64 hi; | |
| u64 low; | |
| u64 doit(u64 m, bool loose_fit) { | |
| if (loose_fit) { | |
| return (m + low) & hi; | |
| } else { | |
| return ((m & ~hi) + low) & (m & hi); | |
| } | |
| } | |
| }; |
There are obvious extensions to handle more than 32 ‘predicates’. We can build a 64-wide version of the above by simply gluing two copies of steps 1-4 together with a shift-by-32 and an OR at the end. A 128-wide version is four copies of steps 1-4 and two separate copies of steps 5-9 with a little bit of logic (a conditional move and an add) to put together our two LZCNT results to turn the result of doing 2 64-bit LZCNTs into a single 128-bit LZCNT.
The above sequence is fast, and reliably so: it doesn’t have any branches and it doesn’t make complex use of memory, so its performance is pretty much constant regardless of input.
It can be made faster if we take a few shortcuts – suppose we have plenty of room in our model, whether it be 32, 64 or 128 bits. We might have, say, 4 strings with 5 characters each, so we’re consuming only 20 slots in a 32-bit model. In this case, why ‘dig holes’? Instead, we can reserve a slot (“gutters” instead of “holes”?) at the high end of the string with a guaranteed zero compare – this means that all we need to do is add our low mask and filter out the carries from the high end, so the ANDN/ADD/AND/AND sequence loses 2 instructions. We refer to this as the “loose fit” model as opposed to the “tight fit” model.
Here are the performance numbers in nanoseconds on a 4.0 Ghz SKL workstation:
| Fit | Predicate Count | ns per sequence (throughput) |
| Loose | 32 | 0.888 |
| Loose | 64 | 1.38 |
| Loose | 128 | 2.82 |
| Tight | 32 | 1.14 |
| Tight | 64 | 1.65 |
| Tight | 128 | 3.37 |
I describe these as throughput numbers, because you won’t get a single SMH lookup done at anything like these speeds – the latency of these sequences is much higher than the throughput you can get if you have lots of these sequences to do.
A future blog post will look into generalized ways to measure this latency specifically (I had a unconvincing experiment with LFENCE). In the meantime, be sure to think carefully about experiments where you “do something in N cycles” where you actually mean “doing 10,000 somethings is N*10,000 cycles” I recommend the following three step program. 1) Cook 18 eggs in a pot for 3 minutes. 2) Convince yourself that throughput == latency. 3) Throw away your original eggs, cook another egg for 10 seconds and bon appétit!
Here’s a debug output showing a couple iterations of one of our models (SMH32-loose, the simplest model). I use underscore instead of zero as it’s easier to read:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| 109 111 117 115:101 0 0 0| 0 0 0 0: 0 0 0 0|109 111 117 115:101 0 0 0| 0 0 0 0: 0 0 0 0| input | |
| 0 1 2 3: 4 128 0 1| 2 3 4 128: 0 1 2 128| 0 1 2 128:128 128 128 128|128 128 128 128:128 128 128 128| shuf_mask | |
| 109 111 117 115:101 0 109 111|117 115 101 0:109 111 117 0|109 111 117 0: 0 0 0 0| 0 0 0 0: 0 0 0 0| shuf result | |
| 109 111 111 115:101 255 109 111|117 115 101 255: 99 97 116 255|100 111 103 255:255 255 255 255|255 255 255 255:255 255 255 255| cmp_mask | |
| 255 255 0 255:255 0 255 255|255 255 255 0: 0 0 0 0| 0 255 0 0: 0 0 0 0| 0 0 0 0: 0 0 0 0| cmp result | |
| 11_11_11111______1______________________________________________ input to gpr-smh | |
| _____1_____1___1___1____________________________________________ hi | |
| 1_____1_____1___1_______________________________________________ low | |
| __111______11___11______________________________________________ after_add | |
| ___________1____________________________________________________ ret | |
| Result: 25 | |
| 99 97 116 0: 0 0 0 0| 0 0 0 0: 0 0 0 0| 99 97 116 0: 0 0 0 0| 0 0 0 0: 0 0 0 0| input | |
| 0 1 2 3: 4 128 0 1| 2 3 4 128: 0 1 2 128| 0 1 2 128:128 128 128 128|128 128 128 128:128 128 128 128| shuf_mask | |
| 99 97 116 0: 0 0 99 97|116 0 0 0: 99 97 116 0| 99 97 116 0: 0 0 0 0| 0 0 0 0: 0 0 0 0| shuf result | |
| 109 111 111 115:101 255 109 111|117 115 101 255: 99 97 116 255|100 111 103 255:255 255 255 255|255 255 255 255:255 255 255 255| cmp_mask | |
| 0 0 0 0: 0 0 0 0| 0 0 0 0:255 255 255 0| 0 0 0 0: 0 0 0 0| 0 0 0 0: 0 0 0 0| cmp result | |
| ____________111_________________________________________________ input to gpr-smh | |
| _____1_____1___1___1____________________________________________ hi | |
| 1_____1_____1___1_______________________________________________ low | |
| 1_____1________11_______________________________________________ after_add | |
| _______________1________________________________________________ ret |
The curious can go to Github and poke the system with a stick. I cannot guarantee that it won’t fall over; this project is very preliminary.
SMH: Full Sequence
(I will not illustrate this with a movie reference)
At this point, you might be excused for wondering why I called SMH the “Swiss Army Chainsaw”. The instantiation above is pretty simplistic and seems to be covering literals only. The codebase as it stands really only allows this; there’s no compiler to do anything but literal prefixes.
However…
1. Shuffle allows discontinuous things to be compared
Because we are using shuffle, we don’t have to select contiguous parts of a string. Better yet, we don’t have to pay for bits of the string we don’t select to compare on. Using regex notation, the very same sequence could just as easily match /a…b/s as /ab/ and both take the same number of predicate slots.
This means we can range over data structures (subject to our limit of 16 bytes; more on that later); we don’t just have to compare strings in buffers.
2. The full sequence allows masking, ranged comparison and negation
The full sequence adds a couple extra SIMD instructions to the front-end, and changes the nature of the comparison from ‘equal’ to ‘greater-than’.
Inserting an AND into our sequence allows us to carry out a ‘masked’ comparison. This allows us to do some fairly simple things – e.g. make caseless comparisons of alphabetic ASCII characters, check individual bits, or look for a range of values like 0x0-0x3 (but not an arbitrary range).
But even more fun – leave the AND into the sequence and subsequently carry out a subtract and change the comparison to ‘greater-than’ comparison (PAND, PSUBB, PCMPGTB).
This gives us all the old power we had before (if we want to target a given value for ‘equal-to’, we simply use PSUBB to ensure that it’s now at the maximum possible value (+127, as the AVX2 comparison is on signed byte) and compare-greater-than with the value +126. However, we can now also detect ranges, and we can even negate single characters and ranges – it’s just a matter of picking out the right subtract (really, PADDB works just as well) and compare values.
I admit I have not really thought through whether there is interesting power granted by the combination of PAND and the PSUBB/PCMPGTB together; I have really only thought about these in a one-at-a-time fashion. It might be better to follow the PSUBB with the PAND. Insights welcome.
3. The bit arithmetic at the end of the sequence can model more than just ADD
The sequence – whether ‘loose model’ (ANDN, ADD, AND, AND) or the ‘tight model’ (ADD, AND) – carried out over the general purpose registers is used to calculate a series of ANDs of variable length bitfields and produce exactly one result per bitfield.
It has more possibilities:
- With a bit of work, it’s possible to handle overlap within the predicates. Suppose we have two strings “dogcow” and “dog”. We can overlap these as long as we either are (a) using the loose model (so we have a safe spot after ‘dogcow’ already) or (b) we separate our ‘dig our holes’ masks and our ‘extract the final comparison masks’. After all, if we overlap “dogcow” and “dog” we don’t want to ‘dig a hole’ at ‘g’, or else we don’t get a carry all the way to the ‘w’. So in a tight model we will still ‘dig a hole’ at “w” but we will have to treat seeing a ‘1’ after than process is done differently – in fact, we will find a match for all of the bolded characters in “dogcow“.
Note we also need to make sure that the index for successfully seeing “dog” is copied not just to the slot corresponding to “g”, but also “c” and “o”, as if we see “dogco” that’s a match for “dog” but not “dogcow”.
- Bizarrely, we can handle OR over some predicates, in some order, and even nest at least one AND-term within that OR (but not two).
So, suppose we wanted to match (in regex notation) /ab[cx]/ – “a, followed by b, followed by c or x”. We could use 4 slots, comparing the first 2 characters in the typical way, then using 2 byte-predicates against the third. We would then, instead of adding the equivalent of binary 0b0001 (the way we would for, say /abcx/), we add binary 0b0011 – so either the ‘c’ matching or the ‘x’ matching will cause a carry out of our last 2 places. The only difference that results is what’s left behind in bits we don’t care about anyway.
Even more odd: suppose we wanted to match /ab(cd|x)/. We can still do this – by ordering our predicates to match a, b, x, c and d in appropriate places. We then add 0b00101 to the mask, which gets the carry we need iff we have “cd” or “x”.
It is not possible to do this trick for an arbitrary combination and something as simple as /ab(cd|xy)/ cannot be done. Only a boolean function where some ordering of the variables allows us to arrange all possible ‘true’ values above or below all possible ‘false’ values can be handled in this way.
In anyone has any theoretical insight into how to express which functions can and can’t be modeled, please let me know!
Future thingies
Needless to say, this can all be made far more powerful (in case it wasn’t powerful enough) with better instructions. While my long-standing love affair with PSHUFB has already been demonstrated and will be demonstrated again, the limitation of 16-character range is irritating. VBMI and VBMI2 in particular introduce more powerful capabilities, and ARM Neon machines already have the means to do generalized byte shuffles over 1-4 registers. There are also possibilities for using larger data items for both shuffles and for the compares (this yields a different set of functionality).
If anyone wants to send me a Cannonlake machine, or a ARM Neon workstation, I’ll give it a shot, without fear or favor.
A pre-shuffle using the existing AVX2 or AVX512 permutes could extend the range of the finer-grain PSHUFB shuffles, although the functionality provided is a bit complex and hard to characterize.
All this will be explored in due course, but not until the basic SMH models have been fleshed out and grown a slightly usable API.
Summary: The Case for the Swiss Army Chainsaw
Armed with the above features, it seems possible to handle an extraordinary number of possibilities. Note that range checks on larger data types than simple bytes, can be (somewhat laboriously) composed with these features, and obviously the whole range of mask checks (as per many network operations) are easily available.
These comparisons could also be used to combine quantitative checks (e.g. is TTL field > some value) with checks of strings or portions of strings in fixed locations.
The fact that we have a logical combination of predicates could allow checking of a type field to be combined with checks that are specific only to the structure associated with that type field – so a data structure which leads with a type field and has several different interpretations for what follows could be checked for properties branchlessly.
Needless to say, actually doing this is hard. The run-time is easy (add 2-3 more instructions!); the compiler and a good API to express all this – not so easy. I’ve illustrated a simple application in this post, and can see more, but have to admit I don’t really quite understand the full possibilities and limitations of this sequence.
Postscript: A Notes on Comparisons To Trent Nelson’s Prefix Matcher
This work has some similarities to the recent Is Prefix Of String In Table work by Trent Nelson. I’d point out a few issues:
- This work is measured in a tighter measurement loop than Trent allows himself, so these numbers are probably artificially better. I’m allowing myself to inline the matching sequence into my measurement code as the SMH sequence here is in a header-only library. I don’t think Trent is doing the same thing so he may be paying some function prologue/epilogue costs. If I get rid of my unrolls and inlines I lose a couple cycles.
- The SMH work presented here isn’t really intended for a larger-scale standalone: it would be more typical to embed it as a second-stage after a first-stage lookup.
- Despite this, out of curiosity, I tried putting Trent’s testing strings into my matcher – one of the strings is too long (I can’t handle >16 length strings) but after that is trimmed to length 16, the matcher can fit those strings in the 128-predicate ‘loose’ model or about 11.3 cycles throughput.
- If one were to select on (say) the first 11 bits or so of the buffer and look up a SMH data structure after 1 layer of indirection (SMH is too big to really make it fun to have 2048*sizeof(SMH) bytes, so indirection is needed) – a simple load, AND, load sequence, it seems obvious that the “loose 32” model could cover the case (3.6 cycles throughput plus added costs from the loads and AND, as well as whatever costs happen from having to go back and forth between multiple SMH sequences rather than using a statically determined set of sequences continuously). As a bonus, this arrangement could strip the first character out of the workload, allowing us to cover 17 characters.
- The SMH code is branch-free and won’t be affected by branch prediction. Trent’s performance analysis doesn’t really cover the effects of branch prediction as it involves benchmarking with the same string over and over again – it is, of course, very hard to come up with realistic benchmarks as there’s no real ‘natural population’ of input to draw from.
- I don’t yet bother to deal with length of the strings, which is naughty. Trent is more responsible. However, the more full SMH model is capable of including length information in its predicate calculations, and an alternative strategy of ‘poisoning’ our input (loading ‘out of range’ characters with values that cannot occur at that position in any valid string – not hard when you only have 16 different strings and no wildcards) is also available.
